Introduction
Enabling AI agents to perform complex spatial analysis tasks such as identifying new city parks within a five‑minute walk of a school requires a reliable, standards‑compliant map engine. The OGC API - Processes specification provides exactly that: a well‑defined set of HTTP endpoints that any client, including AI systems, can invoke consistently.
This post documents the backend I built for my Google Summer of Code (GSoC) 2026 application with 52°North. I focus on the technical decisions, the trade‑offs I evaluated, and how you can reproduce a production‑grade, OGC‑compliant spatial service.
The Code Challenge
Task 1: Deploy and rigorously configure a backend that fully implements the OGC API – Processes standard, including containerization and production considerations.
Task 2: Validate the setup by implementing a meaningful geospatial process, registering it, and exercising the complete execution lifecycle (submission, asynchronous monitoring, and result retrieval).
The following sections walk through my approach, the stack I selected, and the architectural reasoning behind each choice.
Approach Task 1
Before writing any code, it is essential to understand what the OGC API – Processes standard actually defines.
The specification establishes a common contract for exposing geoprocessing capabilities over HTTP. By adhering to it, we avoid the fragmentation that would otherwise force every GIS backend to invent its own API, making it very difficult for AI agents or generic clients to interoperate.
| Method & Endpoint | Description |
|---|---|
GET /processes | Lists all processes the server can execute. |
GET /processes/{id} | Returns the definition (inputs/outputs) of a specific process. |
POST /processes/{id}/execution | Triggers execution of the chosen process with supplied parameters. |
GET /jobs/{jobId} | Retrieves the current status of an asynchronous job. |
Choosing the Tech Stack
For the implementation I selected pygeoapi. As the reference open‑source implementation of the OGC API standards, it guarantees strict compliance out of the box and provides a minimal, extensible Python framework.
Why pygeoapi over a custom solution? Building a standards‑compliant server from scratch would require re‑implementing request validation, OpenAPI generation, and many edge‑case behaviours that the OGC community has already codified. Leveraging pygeoapi lets me focus on the domain‑specific process logic while trusting the underlying stack to handle protocol details.
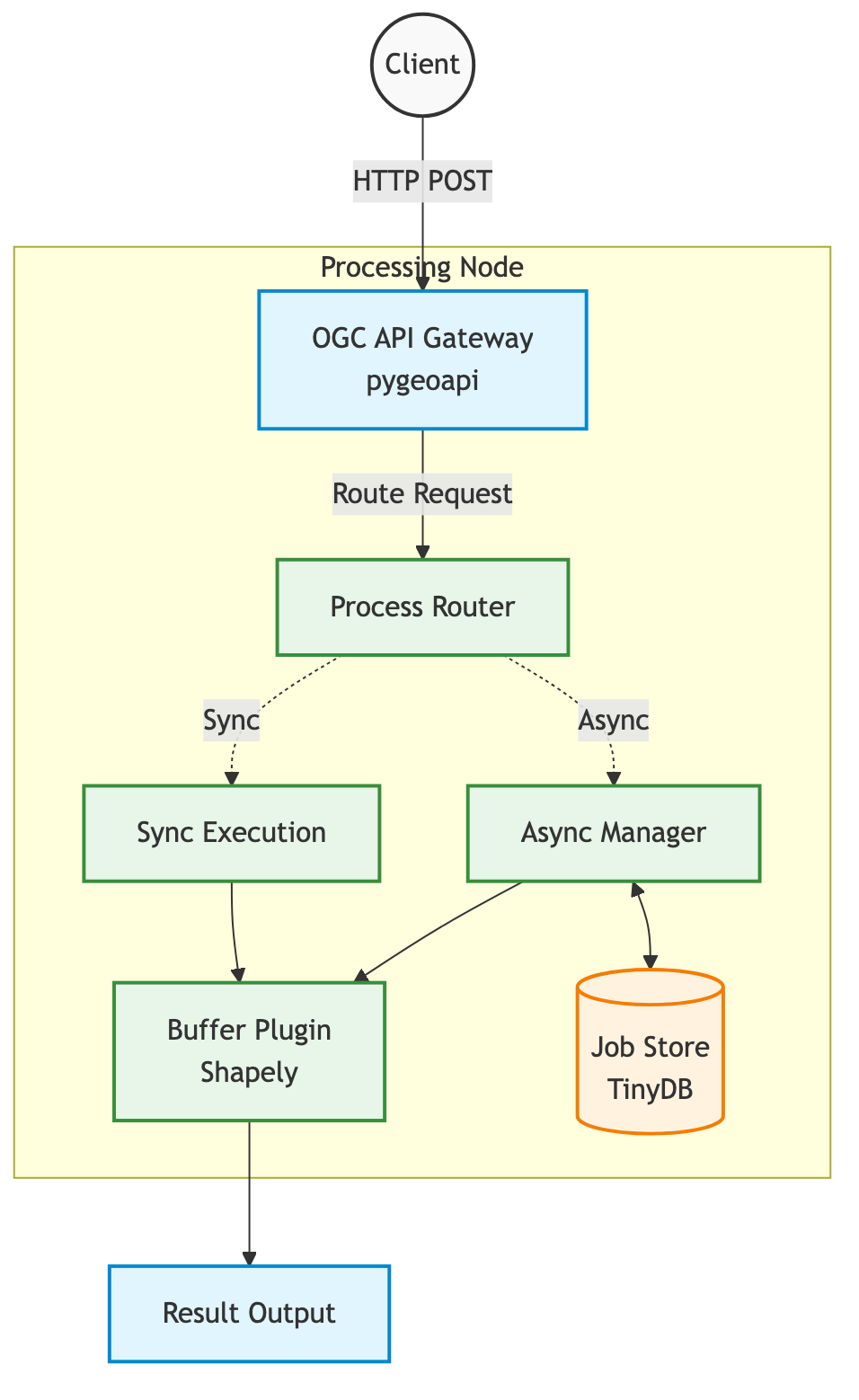
- Execution Environment (Docker Container): Guarantees reproducible builds and isolates dependencies.
- Web Server Gateway (Gunicorn): Provides a robust, production‑ready HTTP front‑end.
- Server Engine (pygeoapi on Flask): Interprets requests, enforces OGC compliance, and orchestrates processing.
- Spatial Math (Shapely): Performs geometry operations such as buffering.
- State Management (TinyDB): Tracks asynchronous job status in a lightweight JSON store for the prototype.
Approach Task 2: Executing a Spatial Process
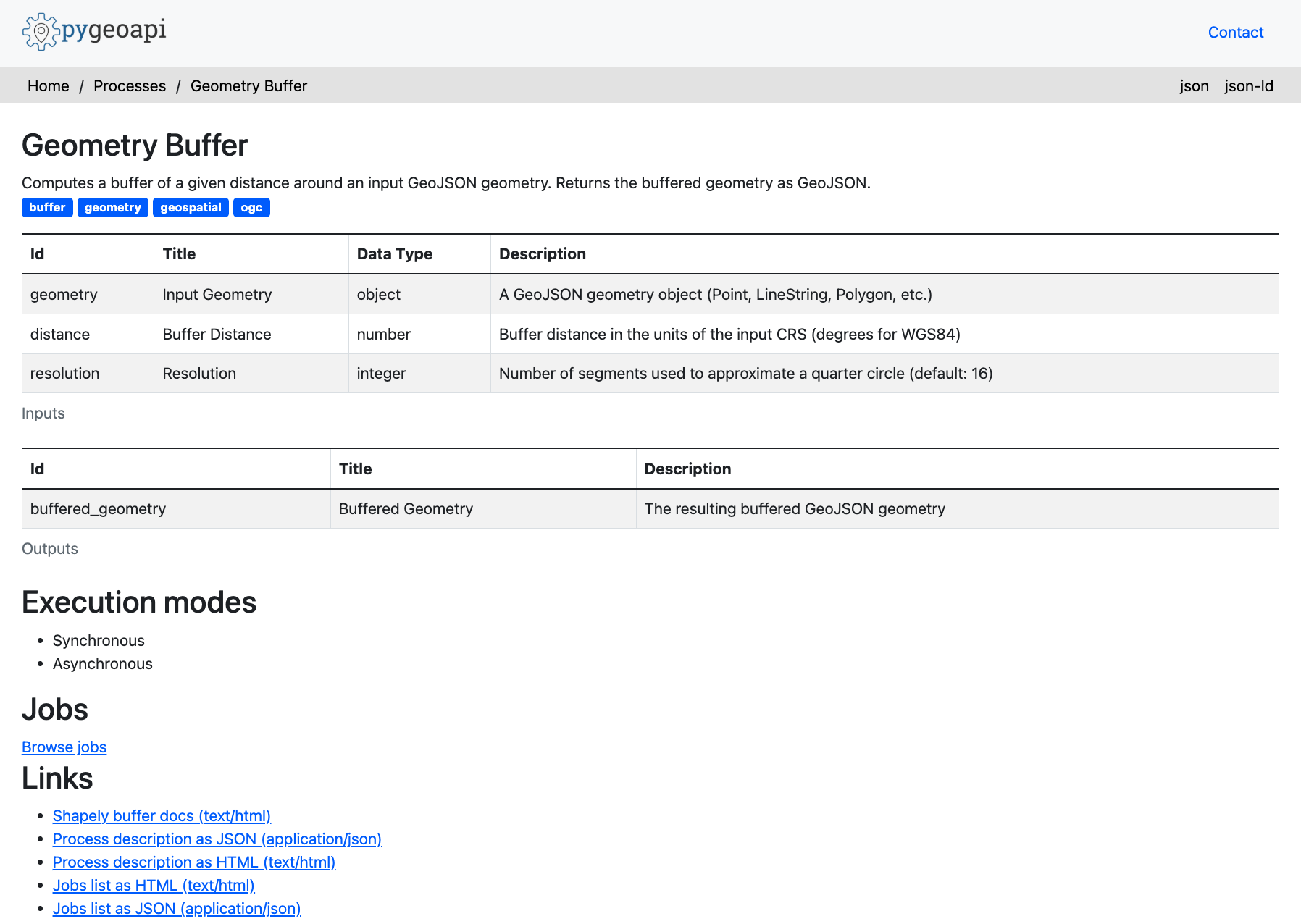
To demonstrate the backend, I implemented a classic geometry buffer process.
A buffer expands a geometry outward by a specified distance, producing a new polygon that represents the area of influence.
In pygeoapi, a process is defined by a Python class that declares its inputs (a GeoJSON geometry and a distance) and its output (the buffered geometry).
PROCESS_METADATA = { 'id': 'buffer', 'title': 'Geometry Buffer', 'inputs': { 'geometry': { ... }, # GeoJSON geometry 'distance': { ... }, # Buffer distance 'resolution': { ... }, # Optional: smoothness }, 'outputs': { 'buffered_geometry': { ... } }, 'jobControlOptions': ['sync-execute', 'async-execute'], } class GeometryBufferProcess(BaseProcessor): def execute(self, data, Outputs=None): geom = shape(data['geometry']) # Parse GeoJSON to Shapely geometry buffered = geom.buffer(data['distance']) # Compute buffer return 'application/json', { 'type': 'Feature', 'geometry': mapping(buffered), # Convert back to GeoJSON 'properties': { ... } }
The processor is registered via pygeoapi's YAML configuration:
resources: geometry-buffer: type: process processor: name: ogc_processes.buffer_process.GeometryBufferProcess
This is how my buffer looked like in the end.
Understanding the ASYNC Lifecycle
The challenge explicitly required exercising the full lifecycle of an asynchronous process execution.
Spatial operations can be computationally intensive; a request that buffers an entire country would exceed typical HTTP timeouts. Therefore, the API must support asynchronous job handling.
My client script follows these steps:
import requests import json url = "http://localhost:5001/processes/geometry-buffer/execution" # GeJSON Polygon and buffer distance payload = { "inputs": { "geometry": { "type": "Polygon", "coordinates": [ [[0.0, 0.0], [1.0, 0.0], [1.0, 1.0], [0.0, 1.0], [0.0, 0.0]] ] }, "distance": 0.5, "resolution": 4 } } headers = {"Prefer": "respond-async"} print(f"Sending POST request to:{url}") print("Headers:", headers) print("\nRequest Payload: ") print(json.dumps(payload, indent=2)) try: response = requests.post(url, json=payload, headers=headers) if response.status_code == 201: print("\nResponse Status Code: 201 Created (Async job accepted)") job_url = response.headers.get("Location") print(f"Tracking Job at: {job_url}") # Poll for job completion import time while True: time.sleep(2) print("Polling status...") status_res = requests.get(job_url) status_json = status_res.json() status = status_json.get("status") print(f"Current Status: {status}") if status == "successful": print("Job completed successfully! Fetching results...") results_res = requests.get(f"{job_url}/results?f=json") print("Final Buffer GeoJSON Geometry: ") try: # Attempt to parse json directly print(json.dumps(results_res.json(), indent=2)) except json. JSONDecodeErior: # If it's returning raw text or stringified JSON rather than application/ison mime print(results_res.text) break elif status in ["failed", "dismissed"]: print(f"Job failed with status: {status}") break else: print(f"\nRequest failed with status code: {response.status_code}") print(response.text) except Exception as e: print(f"\nAn error occurred: {e}")
- Submission: POST a square geometry to
/processes/geometry-buffer/execution. - Tracking: The server immediately returns
201 Createdwith a uniquejobId. - Monitoring: The client polls
GET /jobs/{jobId}until the status changes tosuccessful. - Retrieval: Finally,
GET /jobs/{jobId}/resultsreturns the buffered GeoJSON.
Sending POST request to: http://localhost:5001/processes/geometry-buffer/execution Headers: ('Prefer': 'respond-async') Request Payload: { "inputs": { "geometry": { "type": "Polygon", "coordinates": [ [ [0.0, 0.0], [1.0, 0.0], [1.0, 1.0], [0.0, 1.0], [0.0, 0.0] ] ] }, "distance": 0.5, "resolution": 4 } } Response Status Code: 201 Created (Async job accepted) Tracking Job at: http://localhost:5001/jobs/1c2df982-1182-11f1-abd0-b156884c0307 Polling status... Current Status: successful Job completed successfully! Fetching results... Final Buffer GeoJSON Geometry: { "geometry": { "coordinates": [ [ [-0.5, 0.0], [-0.5, 1.0], [-0.46193976625564337, 1.191341716182545], [-0.35355339059327373, 1.3535533905932737], [-0.19134171618254486, 1.4619397662556435], [0.0, 1.5], [1.0, 1.5], [1.1913417161825448, 1.4619397662556435], [1.3535533905932737, 1.3535533905932737], [1.4619397662556435, 1.1913417161825448], [1.5, 1.0], [1.5, 0.0], [1.4619397662556435, -0.1913417161825449], [1.3535533905932737, -0.35355339059327373], [1.1913417161825448, -0.46193976625564337], [1.0, -0.5], [0.0, -0.5], [-0.19134171618254486, -0.46193976625564337], [-0.35355339059327373, -0.3535533905932738], [-0.46193976625564337, -0.19134171618254495], [-0.5, 0.0] ] ], "type": "Polygon" }, "properties": { "buffer_distance": 0.5, "buffer_resolution": 4, "input_geometry_type": "Polygon", "result_area": 3.765366864730179, "result_geometry_type": "Polygon" }, "type": "Feature" }
The mathematical result: Our 1x1 square expanded outward represented in GeoJSON geometry.
Here's a visualuzation of our 1x1 square before and after buffering.
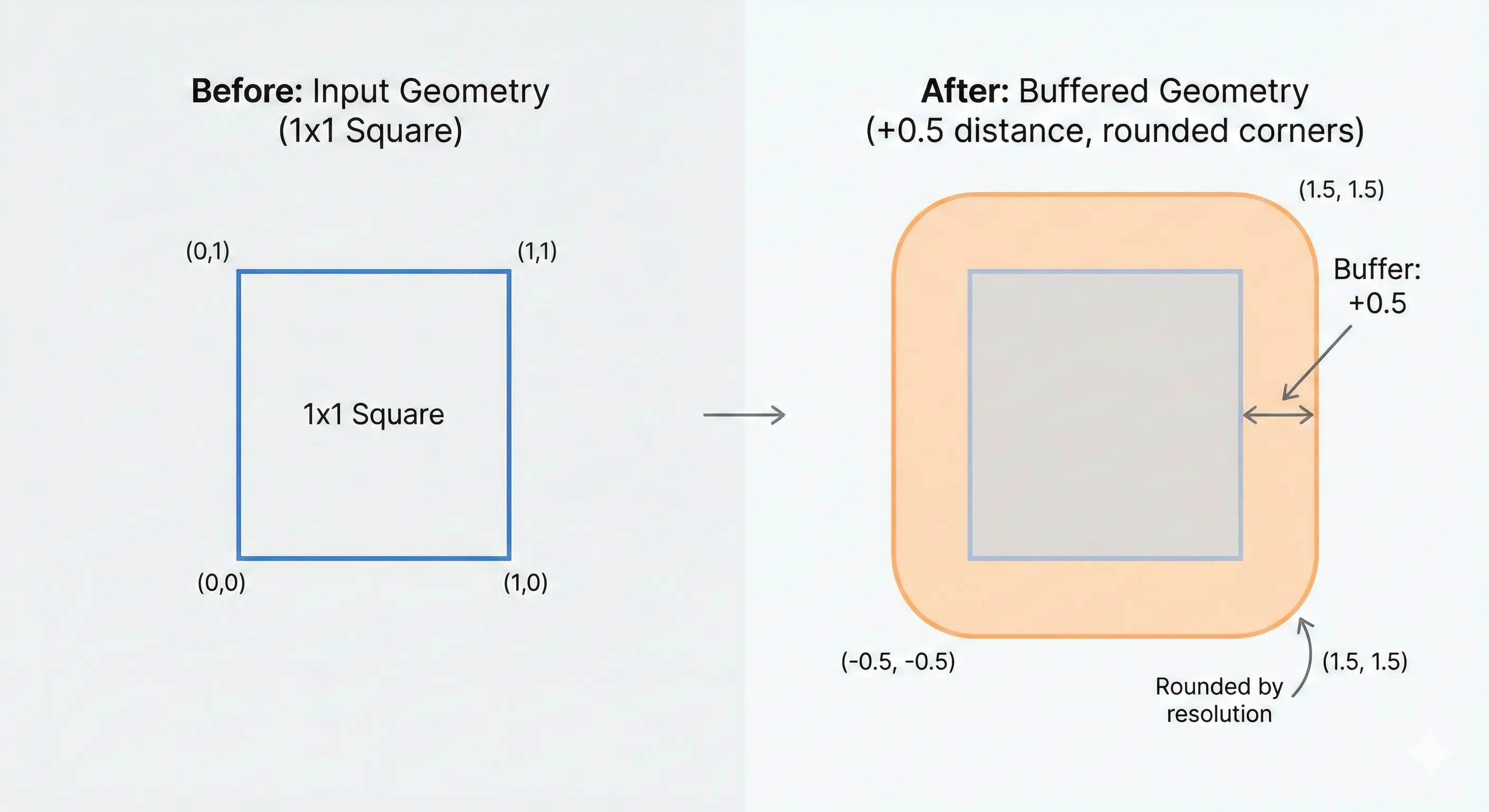
Note how the original square's sharp corners become perfectly rounded in the expansion.
Debugging the Config Error
Containerizing the application initially caused an infinite restart loop. docker ps showed the container in a restart loop
CONTAINER ID IMAGE STATUS 0713fd49497f ogc-mcp-pygeoapi Restarting (255) 4 seconds ago
pygeoapi loads custom processors dynamically, so the container needed to expose the directory containing my code via PYTHONPATH.
ENV PYTHONPATH="/pygeoapi"
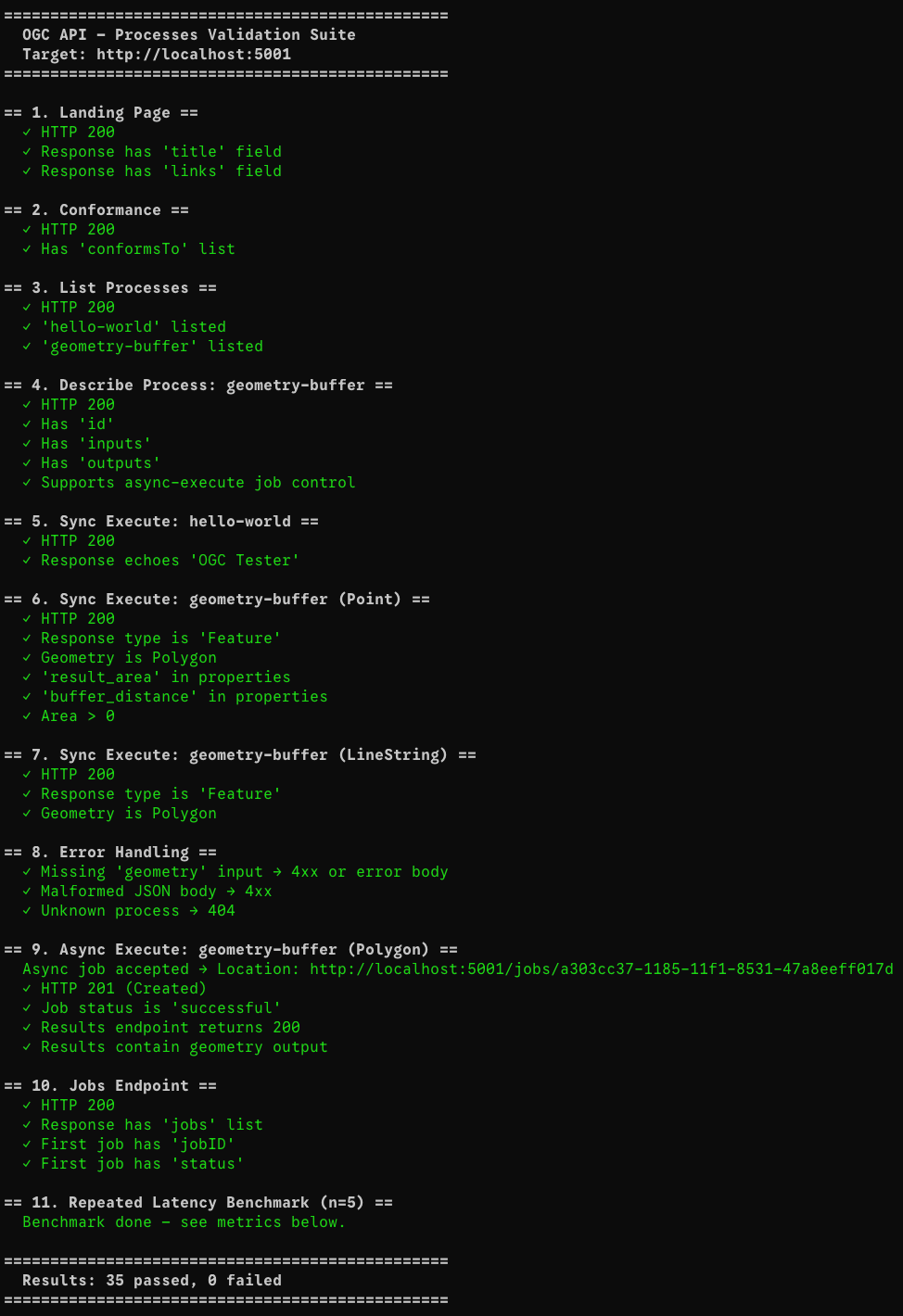
Adding this line to the Dockerfile resolved the import error, and all 35 lifecycle tests passed.
Performance Metrics
After fixing all tests, I ran validate_tests.py against a local Docker container to capture real-world latency for each endpoint. The suite performs 35 assertions and a 5x repeated latency benchmark on the lightweight endpoints.
All measurements are single-node, unwarmed, on localhost (no network hop). They represent the baseline overhead of the full pygeoapi + Gunicorn + Shapely stack.
| Endpoint / Operation | p50 latency | avg latency | Notes |
|---|---|---|---|
GET / | 7 ms | 20 ms | Cold-start variance; warm avg ≈ 7 ms |
GET /conformance | 6 ms | 7 ms | Pure metadata, sub-10 ms consistently |
GET /processes | 9 ms | 10 ms | Process registry scan |
GET /processes/geometry-buffer | 9 ms | 9 ms | Single-process description |
POST /execution — hello-world (sync) | 21 ms | 21 ms | Trivial echo process |
POST /execution — buffer Point (sync) | 37 ms | 37 ms | Shapely buffer call included |
POST /execution — buffer LineString (sync) | 14 ms | 14 ms | Simpler geometry, faster |
POST /execution — async submit | 15 ms | 15 ms | Returns 201 + Location header immediately |
Async job polling (total wait) | 16 ms | 16 ms | Job finished within the first poll cycle |
GET /jobs/{id}/results | 9 ms | 9 ms | TinyDB read + JSON serialisation |
Important takeaway: even the heaviest synchronous buffer operation completes in under 40 ms on localhost. The async path is even faster to respond (15 ms) because the server returns a job handle immediately and the geometry computation happens in the background.
Bottleneck to watch: At scale, the bottleneck would shift from Shapely (which is pure-C and very fast for typical inputs) to TinyDB's file-lock contention under concurrent writes. A PostgreSQL-backed job manager would eliminate this.
What's Next?
1. MCP (Model Context Protocol) Integration
The longer-term goal is to expose these OGC endpoints as MCP tools, so that LLM agents (Claude, Gemini, etc.) can invoke spatial processes directly via natural language. This means wrapping each OGC endpoint in an MCP tool definition and hosting a compliant MCP server alongside pygeoapi.
2. Replace TinyDB with a Production Job Store
TinyDB is a single-file JSON store with no concurrency guarantees. Under load, parallel job submissions will cause write conflicts. The next step is to replace it with a PostgreSQL-backed manager or a dedicated queue like Celery + Redis, which pygeoapi already supports via its manager plugin architecture.
3. True Async Workers
Currently, the "async" mode in pygeoapi runs the process in a thread pool managed by the WSGI server, not a separate worker process. For CPU-intensive tasks (e.g., buffering a country-scale geometry with millions of vertices), the computation should be offloaded to a dedicated Celery worker so the HTTP server remains non-blocking.
4. Additional OGC Processes
The buffer process demonstrates the pattern, but a useful MCP-connected backend would expose a richer library: intersection, union, simplification, area/perimeter calculation, and coordinate reprojection. Each can be implemented as a new BaseProcessor subclass with minimal boilerplate.
5. Authentication & Rate Limiting
A public OGC API endpoint needs OAuth 2.0 / API-key authentication and per-client rate limiting to prevent abuse. pygeoapi supports security plugins, and a reverse proxy layer (NGINX or AWS API Gateway) can enforce per-IP limits at the edge.
6. CI/CD Pipeline
The natural next step is to run tests on every pull request via GitHub Actions, building the Docker image, spinning up the container, running the test suite, and failing the build if any check regresses.
Thanks for reading
You can check out my full open-source codebase, including the Docker setup and validation scripts, right here on GitHub.
Note: AI (LLMs) were used in this blog to correct any punctual or grammatical errors or for refinement of UI/UX only; the content was written by my hands.